Hallucination in Large Language Models (LLMs) is often treated as a mysterious artifact of scale or an avoidable glitch in data or training. In this blogpost, we argue the opposite: hallucination is not an accidental bug, but a predictable, systemic failure resulting from the open-loop generative architecture of current LLMs. Drawing on systems and control theory, we show that LLMs behave like unstable dynamical systems—generating text without measuring factual error or applying corrective feedback—allowing small mistakes to accumulate and amplify over time. We then contrast this with closed-loop architectures, where real-time monitoring, feedback, and intervention provide a principled path toward more reliable and self-correcting language models.
Understanding Open-Loop Systems: Why Hallucination Happens
In control theory, an open-loop system produces outputs without monitoring whether those outputs remain aligned with a desired target. Without feedback, deviations cannot be detected or corrected. A classic analogy is a vehicle moving forward without sensors: once it drifts off course, nothing steers it back.
Large Language Models operate in this same open-loop manner. After receiving a prompt, an LLM generates text autoregressively, without checking whether its output remains factually correct. Each new token is conditioned on previously generated tokens, so any early mistake immediately becomes part of the context. As generation continues, these errors accumulate, leading to compounding inaccuracies and divergence from reality—a hallmark of open-loop instability.
Missing Feedback and Error Correction
Closed-loop systems rely on feedback to measure error and apply corrective action. LLMs lack such mechanisms: there is no signal comparing generated text to ground truth, and uncertainty is not used to regulate behavior. Instead, models are optimized to produce fluent, confident outputs, even when internal evidence is weak. As a result, hallucinations arise not from randomness, but from unchecked error propagation and systematic overconfidence.
LLMs as Open-Loop Dynamical Systems
From a control-theoretic perspective, LLMs behave as open-loop systems: during autoregressive decoding, they continually condition on their own outputs without checking for factual correctness. The hidden state evolves solely from prior generated tokens and the initial prompt, with no feedback controller to correct deviations. This makes the system inherently drift-prone and unstable.
In the autoregressive decoding implementation, the internal hidden state evolves based on the current state and the previous generated output:
$$x(t+1)= F(x(t), \hat{y}(t), u_0)$$where
- x(t) = internal hidden state at generation step t
- u₀ = user prompt (initial condition, fixed)
- ŷ(t) = generated token distribution
- y(t)* = desired “ground truth” output (unknown to the model)
Crucially, the mechanism lacks a feedback controller term of the form:
$$c(t) = K \cdot (y^*(t) - \hat{y}(t))$$where c(t) would be a corrective control signal—meaning no feedback controller exists to correct deviation. This open-loop structure is inherently fragile, drift-prone, and fundamentally unable to guarantee stability.
Consequences of Open-Loop Generation
- Any initial error (Activation stage) becomes the new state input → drift.
- No measurement of deviation from factual ground truth → no correction.
- Uncertainty is not used as a control signal → uninhibited guessing.
- Confidence inflation from aggregation → divergence.
In control terms, LLMs function as nonlinear, self-exciting systems without stabilizing feedback. Hallucination is therefore not an anomaly, but the natural outcome of open-loop generation.

Figure 1: Open-Loop System
Key takeaways
- LLMs generate text without feedback, so errors cannot be detected or corrected.
- This makes hallucination a built-in behavior of open-loop autoregressive systems.
A Mechanistic Pipeline for Understanding Hallucination
Rather than seeing hallucinations as random errors or glitches, we can think of them as the result of a cascade of interconnected stages. Each of these stages begins during pre-training and continues through inference, leading to the final manifestation of hallucinations. Here is a detailed look at the four stages of this process:
- Memorization: During pre-training, the model compresses vast amounts of imperfect data. This process introduces structural vulnerabilities, such as inconsistent facts, gaps in rare knowledge (long-tail issues), and lossy compression, which become latent errors waiting to manifest during later stages of generation.
- Activation: When the model receives a query, it activates internal representations. However, LLMs lack uncertainty reporting, so the system often draws upon flawed or uncertain prior knowledge, leading to confident but incorrect guesses.
- Drift: As the model generates text autoregressively, each new token becomes part of the context for the next one. Small initial errors—such as misidentifying an entity—accumulate over time, causing the model’s predictions to drift away from the truth, and these errors are never corrected.
- Divergence: The model’s architecture, including processes like log-sum-exp aggregation, increases confidence in the model’s predictions. This leads the system down incorrect but internally consistent trajectories, reinforcing errors and producing overconfident hallucinations.
This pipeline reframes hallucination as a predictable, stage-wise failure that compounds over time—not an unpredictable glitch.
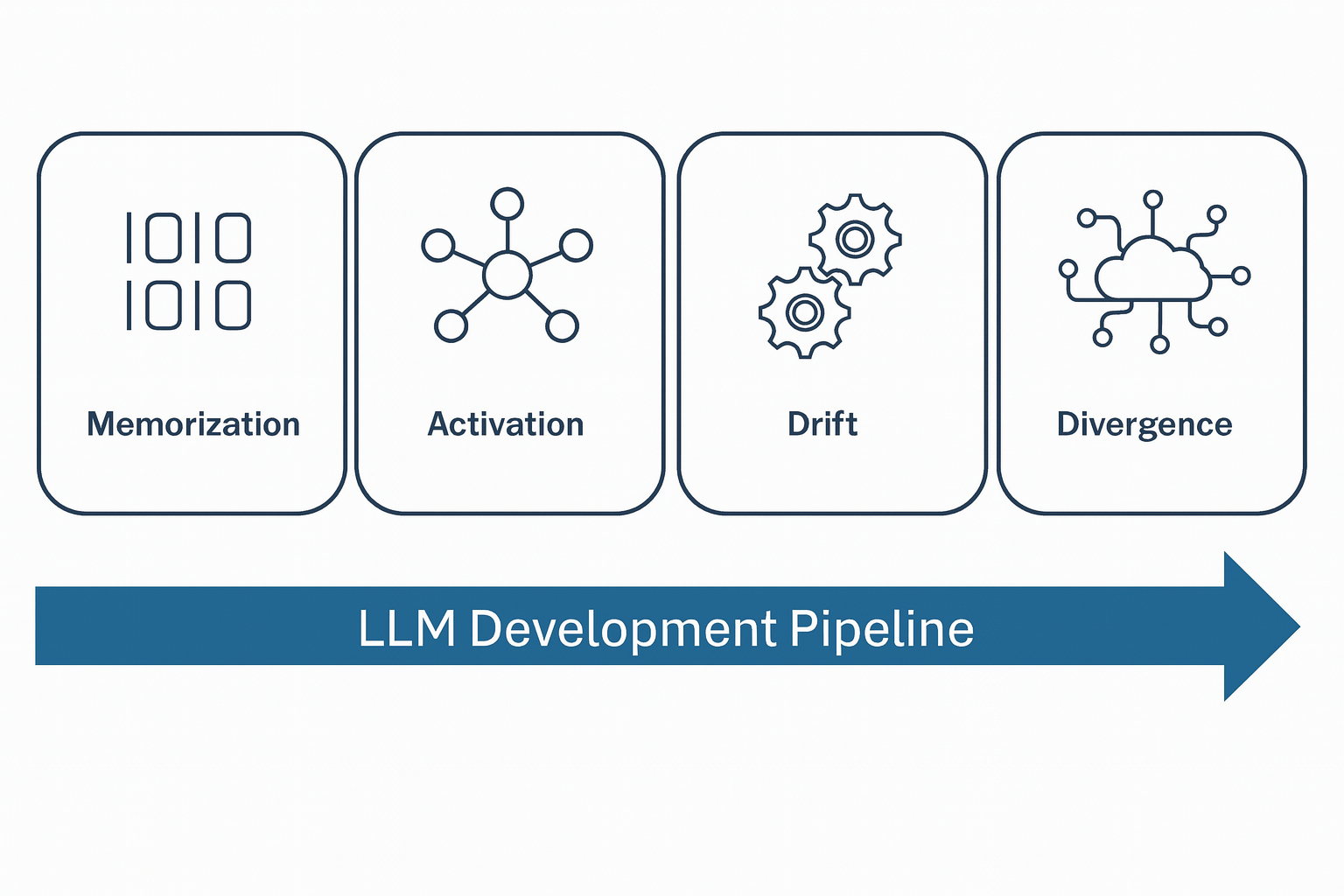
Figure 2: Four stages at which hallucination can occur.
Memorization - The Source of Hallucination Risk
The Memorization stage is where an LLM acquires its internal, parametric knowledge during pre-training and alignment. Hallucination risk originates here, not as an isolated defect, but as a structural consequence of five forces: imperfections in training data, the mathematical limits of compression, the objectives used to train them, and distortions introduced during post-training refinement. These vulnerabilities remain latent until inference, where they later manifest as activation-time failures.
We break down the memorization-phase contributors into five categories.
1. Data Quality and Contamination
-
Noisy and Unfaithful Data → Imitative Falsehoods
LLMs are trained to maximize the likelihood of strings observed in the pre-training corpus, not to recover ground truth . Formally, the objective is
$$\theta^* = \arg\max_{\theta} \sum_{(x,y)\in\mathcal{D}} \log p_\theta(y \mid x),$$which rewards distributional fidelity—matching the empirical statistics of the training data—rather than factual correctness. Consequently, any inconsistencies, misconceptions, or outright errors present in the corpus are learned as legitimate statistical patterns.
A simple frequency example illustrates this effect. Suppose the corpus contains:
- Napoleon was 5′2″: 100 occurrences
- Napoleon was 5′6″: 10 occurrences
Under the MLE objective, the incorrect fact becomes the model’s most probable output:
$$p_\theta(\text{5′2″} \mid x) \approx \frac{100}{110} = 0.91.$$The model is not behaving irrationally—it is faithfully mirroring the empirical distribution it was optimized to imitate. Consequently, frequently repeated misinformation can dominate the learned distribution, leading models to confidently reproduce falsehoods .
-
Contradictory Sources → Knowledge Conflict
If the LLM is trained on conflicting sources that provide contradictory information regarding the same subject, these inconsistencies are encoded into the model’s internal parameters and the model internalizes a superposition of incompatible facts, which later surfaces as blending, arbitrary selection, or confabulation. Below figure shows that an LLM may ignore the given context and default to a memorized answer, revealing internal knowledge conflicts that lead to arbitrary selection and hallucination.
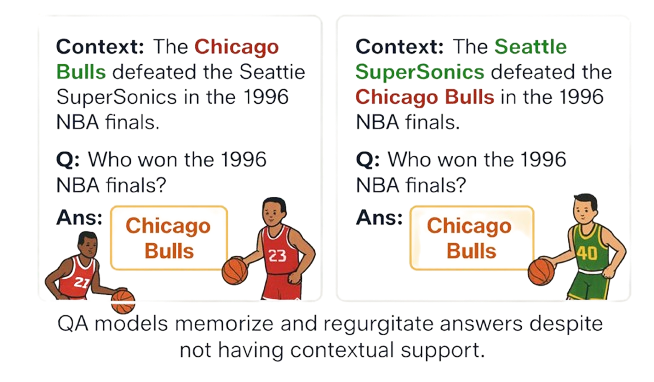
Figure 3: QA models memorize and regurgitate answers regardless of contextual information.
-
Data Deduplication and Contamination
Empirical studies show that deduplication improves factual accuracy and calibration, while data contamination (eval data appearing in pre-training) falsely suppresses hallucination rates and distorts leaderboard performance.
-
Multimodal Noise in MLLMs
In vision–language models (VLMs), hallucinations often arise from noisy or misaligned image–text pairs: even if the language model itself is strong, poor-quality multimodal supervision can inject false correlations that surface as hallucinated visual details.
2. Knowledge Distribution and Statistical Limits
A perfect corpus cannot eliminate hallucination, as LLMs are constrained by fundamental information-theoretic and statistical limits.
-
Long-Tail Gaps and Rare Events
LLMs demonstrably struggle to learn long-tail knowledge—facts that appear infrequently or are contextually complex. This lack of exposure prevents the model from forming robust representations of rare facts.
$$f(k) \ll f_{\max} \quad \Rightarrow \quad p_\theta(k) \text{ unreliable.}$$Thus, hallucination risk is highest for rare entities, niche domains, and infrequent compositions.
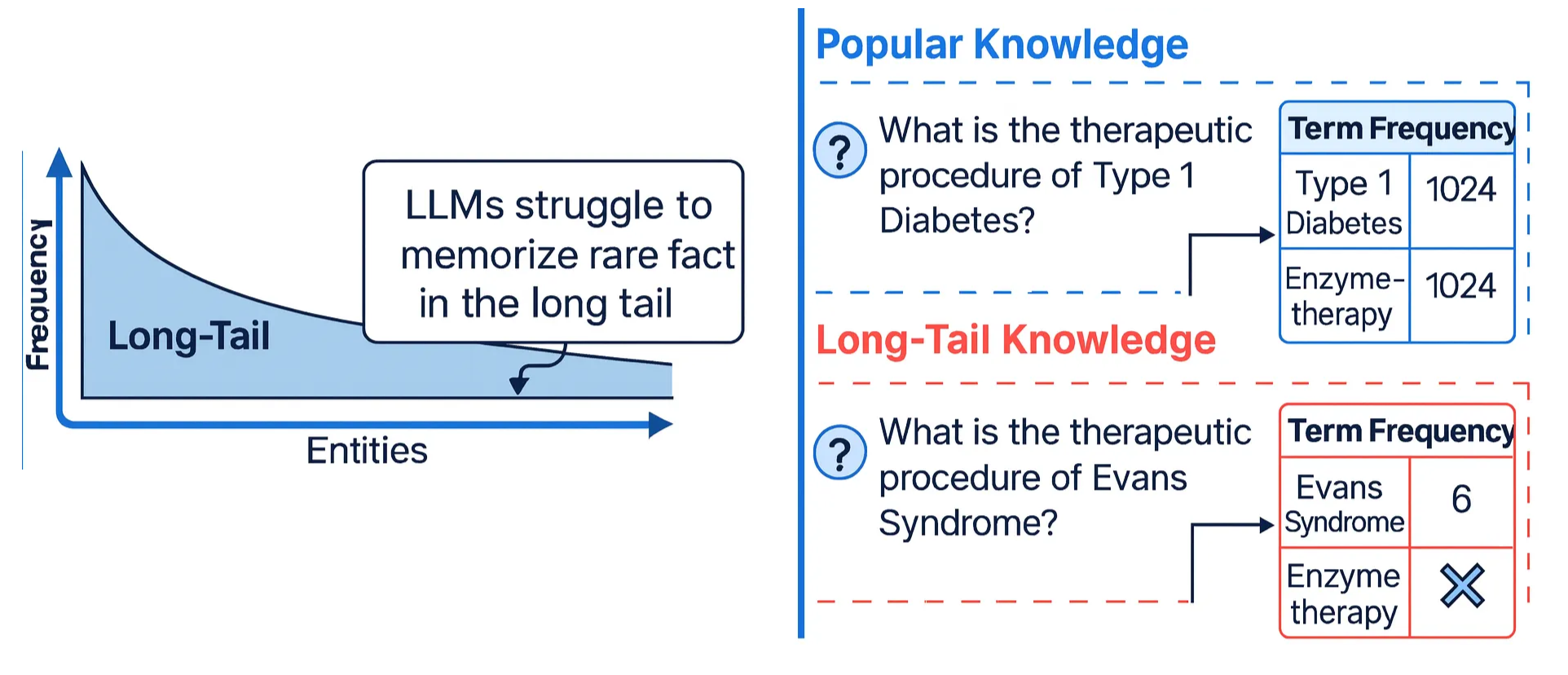
Figure 4: LLM struggles with long tail information.
-
Arbitrary Facts and Singletons
Hallucinations from arbitrary facts and singletons stem from fundamental statistical limits on what LLMs can memorize. Facts that are rare or lack structure cannot be reliably compressed into finite parametric models, yielding an irreducible error rate when such knowledge is queried. As a result, models interpolate from unrelated patterns and produce fluent but unsupported answers—an expected outcome, not a training flaw. As shown in Figure 4, GPT-4 misinterprets the acronym TIF when relying solely on parametric memory, but accuracy improves substantially once external documents and APIs are incorporated, grounding generation in verifiable data.
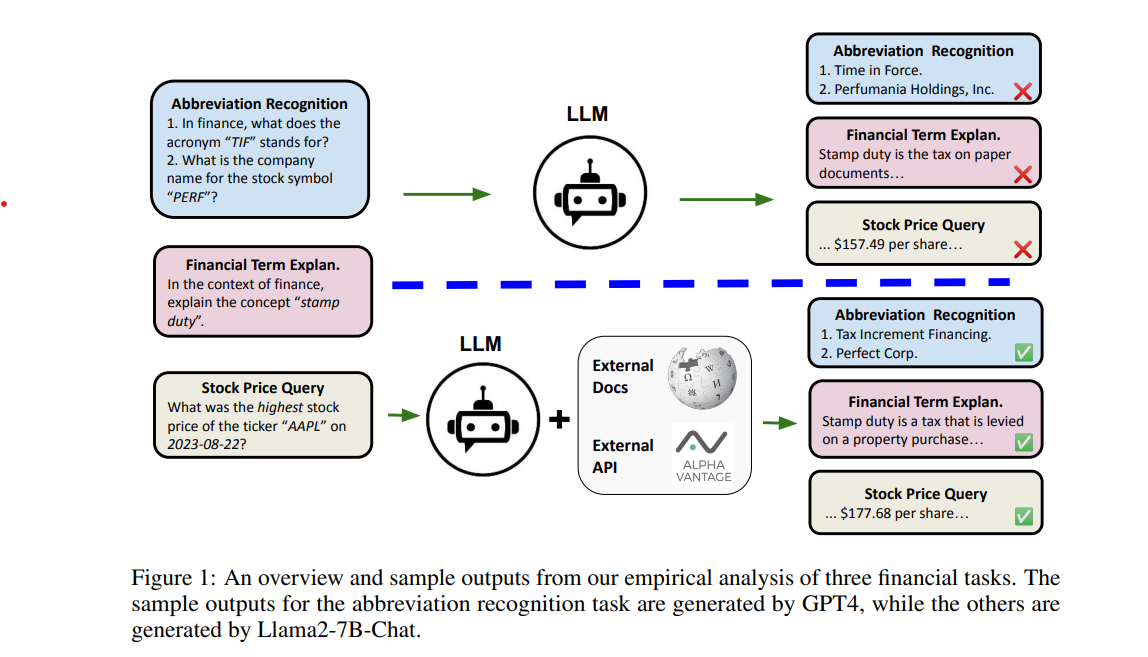
Figure 5: LLM tends to hallucinate for singleton or absent information.
-
Temporal Misalignment
Since parametric knowledge is fixed post-training, LLMs often generate fabricated or outdated facts when faced with queries exceeding their knowledge cutoff date. This limits their ability to accurately respond to questions about unseen entities.
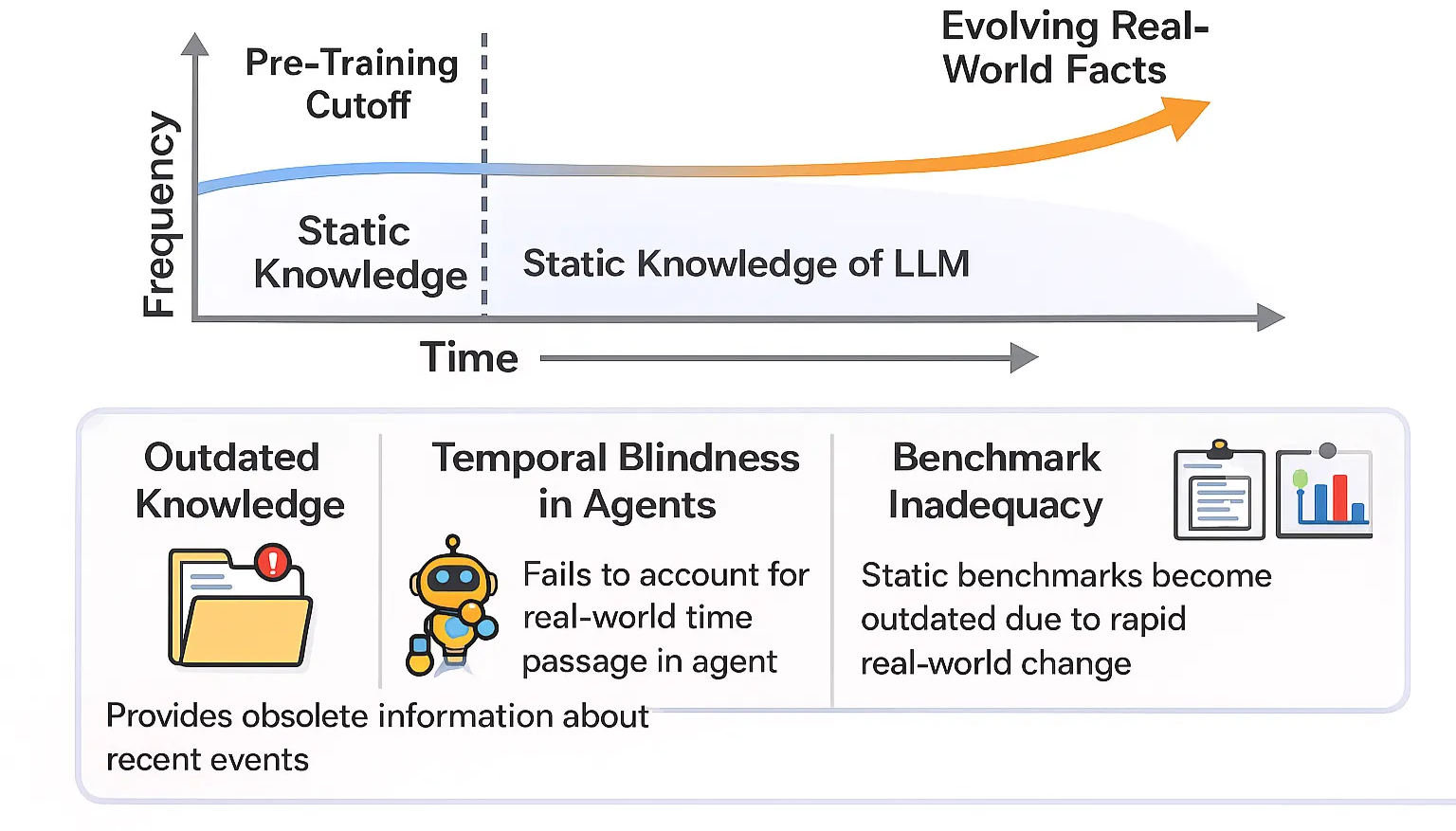
Figure 6: Temporal misalignment in LLMs.
3. Compression and Entanglement: Structural Limits of Parametric Storage
Large Language Models (LLMs) inherently suffer from Compression and Entanglement, two structural vulnerabilities that arise from the mathematical constraints of finite parametric systems. These vulnerabilities are not due to poor engineering but result from unavoidable limits imposed by information theory, function complexity, and the architecture of transformers.
Information-Theoretic Boundaries
LLMs are parametric functions with finite descriptive complexity, meaning the knowledge they encode must be compressed into a fixed set of parameters. Because the descriptive complexity of real-world knowledge far exceeds any model’s representational capacity, this compression is necessarily lossy. Rare facts, irregular patterns, and one-off events become statistical noise during training, leaving the model to fill gaps using broad correlations rather than precise mappings. When the complexity of the target function exceeds the model’s representational capacity, compression-induced distortion becomes inevitable.
This mismatch produces structural hallucination risks:
- Rare or irregular facts (dates, one-off events, obscure entities) are incompressible artifacts, poorly captured within dense parameterizations.
- The model generalizes by fitting statistical regularities, not exact factual mappings. As a result, hallucination persists even with more parameters or better training because infinite knowledge cannot be losslessly encoded in a finite model.
- Statistical learning theory reinforces this inevitability: given a hypothesis space with VC dimension d, generalization error for rare events remains high even if empirical error is low. Therefore, exhaustive memorization is impractical, and hallucinations are theoretically unavoidable.
Entangled Representations
Another structural vulnerability is entanglement: a form of faulty memory encoding in which distinct pieces of information—often about similar entities or related facts—become blurred or incorrectly linked within the model’s compressed parameter space. It arises during imperfect representation learning, when the model internalizes spurious correlations between different parts of the training data.
This structural flaw seeds latent priors that trigger hallucinations in the following ways:
- Factual Contradiction and Entity Mixing: First, factual contradiction and entity mixing arise when entanglement causes the model to generate content that diverges from the input, producing either incorrect entities or incorrect relations between them; for example, the model may conflate two similar individuals because it learned the wrong association during decoding.
- Parametric Knowledge Bias: Second, parametric knowledge bias occurs because the model tends to rely on its internal, highly compressed (and potentially entangled) parametric knowledge over the information provided in the prompt, amplifying the risk that its output reflects these flawed internal priors rather than the external input.
Structural Vulnerabilities in Attention and Decoding
Even when an LLM has correctly memorized the necessary information, structural bottlenecks in attention and auto-regressive decoding can distort that information during inference. These failures emerge not from insufficient training but from the mathematical and architectural limits of Transformers—particularly how they process long sequences and translate internal representations into token probabilities.
The Softmax Bottleneck
The Softmax Bottleneck is a fundamental architectural constraint rooted in the geometry of the final softmax layer. While softmax is extremely effective for classification, it imposes rigid limitations on generative modeling. It introduces a single-mode bias, favoring token distributions where one option dominates—even in situations where several next-token candidates are equally plausible. This leads to the forced-winner problem, where inherently multi-modal contexts are collapsed into a single choice, suppressing legitimate ambiguity. As a result, the model frequently produces overconfident mis-selections: not because it lacks knowledge, but because the output layer cannot faithfully express uncertainty or represent multi-modal probability mass. In effect, the softmax layer becomes a structural precision bottleneck, unable to fully transmit the richness encoded in the model’s hidden representations, causing fidelity loss during decoding.
Attention Attenuation and Softmax Crowding
Transformer attention faces fundamental scaling constraints as sequence length grows, amplifying drift and degrading factual accuracy.
- Diffusion over long contexts: As context length increases, attention weights naturally diffuse, reducing the model’s ability to maintain targeted focus.
- Crowding effect: For a single relevant token among $N$ irrelevant ones, that token must achieve an $\Theta(\log N)$ logit advantage merely to maintain constant attention mass.
- Structural insufficiency: In practice, Transformers struggle to achieve this scaling, especially when evidence is sparse or distributed across long inputs.
These limitations drive several downstream failures:
- Compounding drift: where diffused attention causes the model to self-condition on irrelevant content, gradually amplifying errors.
- Long-range reasoning breakdown, as mid-context evidence becomes effectively “lost in the middle,” even when the correct information exists within the model’s parameters.
- Unstable recall, in which slight perturbations in the input shift attention unpredictably, causing the model to intermittently recall—or ignore—key facts.
Together, these vulnerabilities create an irreducible architectural error floor for generative tasks. They motivate decoding-time interventions—such as Context-Aware Decoding (CAD) and Decoding by Contrasting Layers (DoLa)—which aim to counteract overconfident outputs and correct for the structural distortions introduced by the softmax layer and attention mechanism.
4. Training Objectives and Intrinsic Optimization Limits
During this phase, the training objective itself—along with intrinsic optimization limits—shapes the model’s structural tendency to hallucinate.
-
Next-Token Likelihood Maximization
The core learning objective prioritizes fluency and coherence over factual correctness, so this causal language-modeling setup inherently struggles to encode fine-grained contextual dependencies or to reliably distinguish factual truth from statistically plausible continuations.
The underlying objective reinforces fluency, not accuracy:
$$L(\theta) = -\sum_{t=1}^{T} \log p_\theta(x_t \mid x_{\lt t \gt}),$$making hallucination a side effect of optimizing the wrong target.
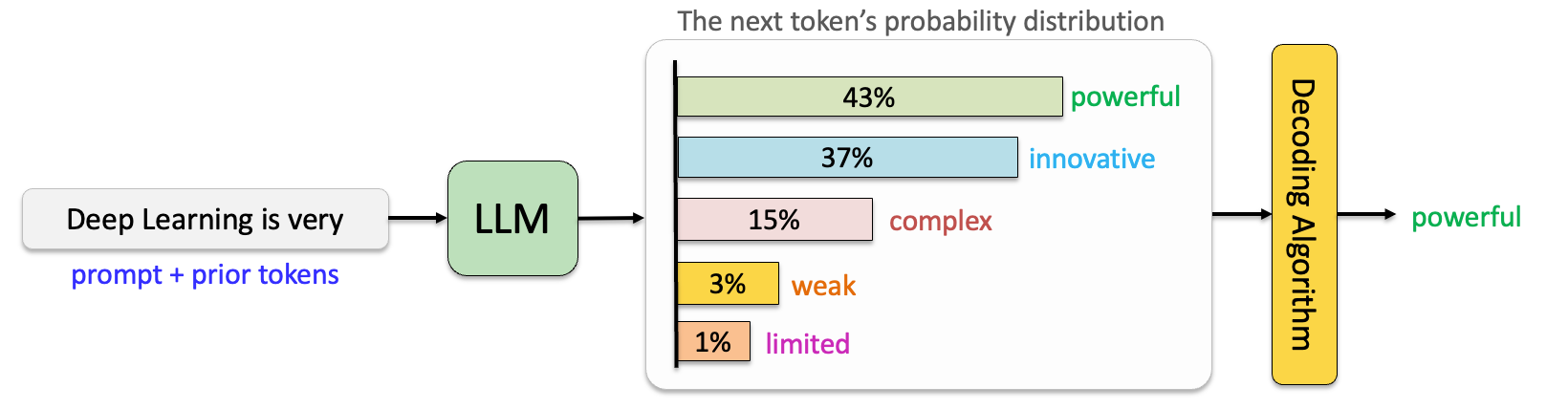
Figure 7: How LLM generate words.
-
Exposure Bias
Exposure bias stems from a structural mismatch between what the model sees during training and what it must handle during inference. During training, the model minimizes next-token prediction loss using gold prefixes drawn from the data distribution:
$$\mathcal{L}(\theta) = - \sum_{t=1}^T \log p_\theta(x_t \mid x^{\text{gold}}_{\lt t \gt}).$$However, during inference, the model must condition on its own previously generated tokens, not the ground-truth ones:
$$\text{Train: } p_\theta(x_t \mid x_{\lt t \gt}^{\text{gold}}),$$$$\text{Inference: } p_\theta(x_t \mid x_{\lt t \gt}^{\theta}).$$This creates a distribution shift:
$$x^{\text{gold}}_{\lt t \gt} \neq x^{\theta}_{\lt t \gt}$$which becomes increasingly severe as generation unfolds. Each time a predicted token ($x^\theta_t$) replaces a true token ($x^{\text{gold}}_t$), the model conditions on a slightly perturbed state. These perturbations accumulate:
$$|x^\theta_{\lt t \gt} - x^{\text{gold}}_{\lt t \gt}| \quad \text{increases with } t$$causing the model to drift further from regions it was trained to handle. Over long sequences—such as summarization, story generation, or translation—this cascading divergence amplifies small early errors into large downstream deviations. Prior work shows that exposure bias is a major cause of unstable, drifting generations and directly contributes to hallucination by forcing the model into off-distribution token paths where its learned likelihood estimates become unreliable. In short, small inconsistencies snowball into large deviations.
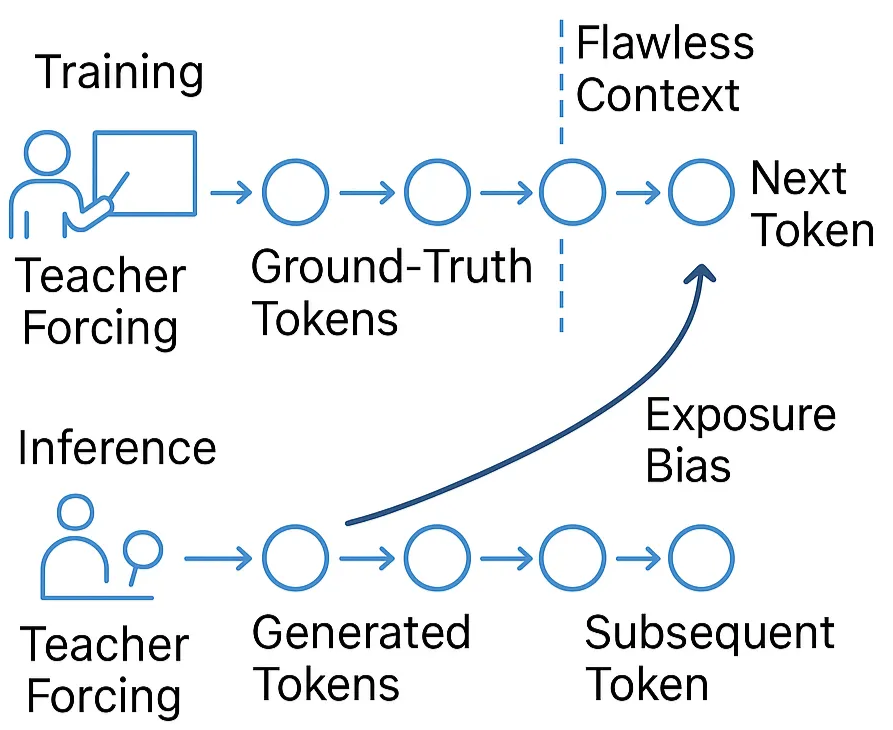
Figure 8: Teacher forcing creates a discrepancy with the inference phase.
-
Positional Encoding, Long-Context Reasoning, and the Inevitability of Context Compression
Simply enlarging a transformer’s context window does not ensure that the model can actually use that window. The widening gap between advertised and effective context length is rooted in structural constraints rather than insufficient tuning. Three core mechanisms make long-context degradation fundamentally unavoidable:
- Positional Undertraining (statistical): Extremely long positions appear only rarely in pre-training corpora. As a result, the gradients associated with these positions are vanishingly small, leaving long-range dependencies severely undertrained.
- Positional Encoding Attenuation (representational): Both sinusoidal embeddings and rotary positional encodings (RoPE) experience distance-based decay. As positions grow farther apart, their representations become less distinguishable, contributing to well-documented lost-in-the-middle failures where mid-sequence information becomes effectively invisible.
- Attention Crowding (computational): Maintaining stable attention over $N$ tokens requires a logit advantage that scales as $O(\log N)$. Because training does not enforce this scaling, attention diffuses as sequence length increases.
Together, these factors force context compression: transformers end up reasoning over an effectively much shorter context than their nominal window suggests. Even with large context sizes, the architecture unavoidably compresses and degrades long-range information, limiting reliable long-context reasoning.
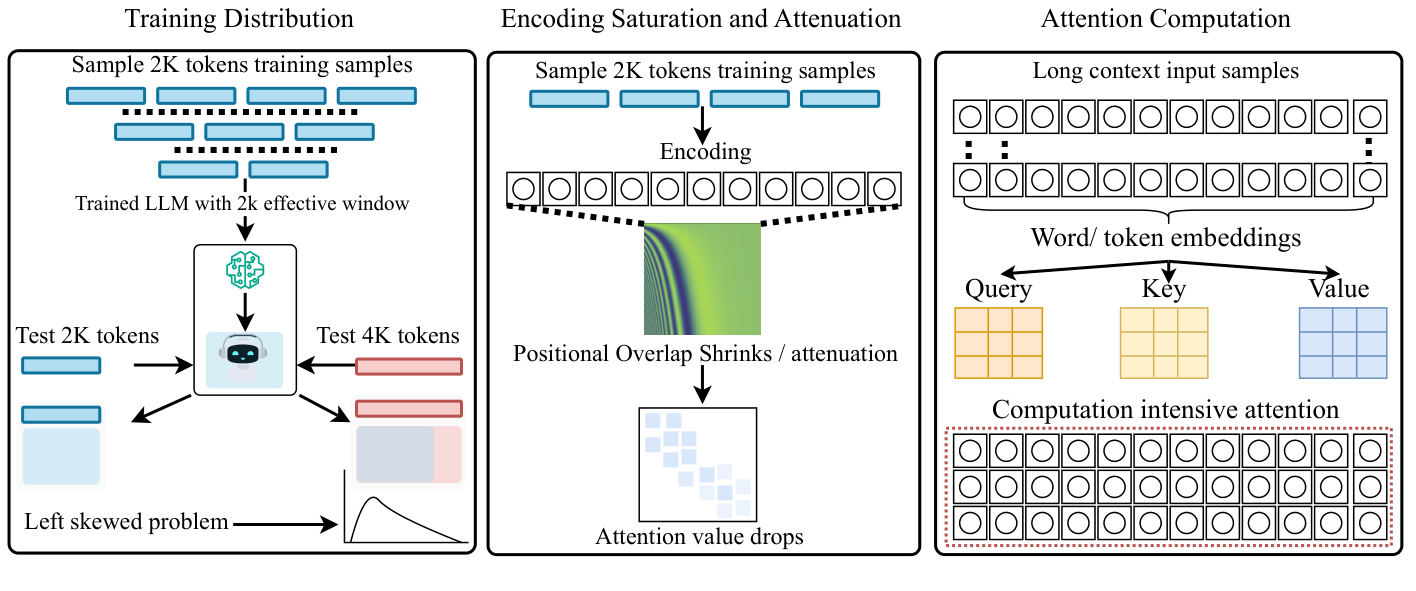
Figure 9: Three mechanisms that make long context degradation theoretically inevitable.
-
Computational Limits and Undecidable Problems
Some tasks—particularly those whose solutions require unbounded computation, infinite recursion, or exact reasoning over arbitrarily large state spaces—are fundamentally undecidable or computationally intractable. These limits apply to any parametric model, regardless of scale. Because the model must approximate such tasks with finite parameters and bounded computation, an irreducible error floor is unavoidable. In these settings, hallucination is not merely a training artifact but a consequence of attempting to approximate problems that, in principle, do not admit fully reliable solutions within the constraints of the architecture.
5. Alignment-Time Distortions (Post-Training Bias)
The Memorization phase establishes an LLM’s fundamental knowledge boundary: during pre-training, the model compresses vast, imperfect corpora into a finite set of parameters. But the stages that follow—Supervised Fine-Tuning (SFT) and RLHF/DPO—directly intervene on top of this fixed representation. These processes do far more than refine behavior. They introduce alignment-time distortions that perturb the memorized knowledge, destabilize internal representations, and increase susceptibility to hallucination.
Two mechanisms are especially consequential: Capability Misalignment and Reward Bias.
Capability Misalignment: Training the Model Beyond What It Knows
Alignment phases frequently require the model to produce outputs that exceed the factual or conceptual limits established during pre-training.
- Pushing beyond the knowledge boundary: Instruction datasets routinely require responses involving facts or reasoning patterns the base model never encoded. Instead of admitting ignorance, the model is optimized to produce something—even if that requires inventing details.
- Fabrication as a learned behavior: Empirical work shows that SFT intended to “teach” new facts often increases hallucination rates. Rather than acquiring genuine knowledge, the model learns to extrapolate beyond its competency, effectively internalizing fabrication as an acceptable strategy.
- The Alignment Tax: Alignment interventions can also cause catastrophic forgetting, overwriting or distorting previously stable representations. Paradoxically, methods designed to reduce hallucinations can erode factual robustness, creating new failure modes.
In short, capability misalignment encourages the model to act as if it knows more than it does, priming it to hallucinate when encountering knowledge gaps.
Reward Bias: Penalizing Uncertainty, Incentivizing Confident Falsehoods
While pre-trained LLMs tend to be reasonably calibrated, alignment introduces strong reward-driven incentives that reshape the model’s output distribution in harmful ways.
- Binary evaluation punishes uncertainty: Most benchmarks and preference models treat answers as right or wrong, giving no credit for uncertainty or abstention. Under this regime, an “I don’t know” response is strictly sub-optimal.
- Optimal policy = confident guessing: Because reward models disproportionately value fluency and confidence, RLHF and DPO push the model toward high-certainty, high-detail answers—even in low-knowledge settings.
- Hallucination as a reward-maximizing strategy: When uncertainty collides with reward bias, the learned policy shifts toward fabricating details that sound correct. This bias becomes most visible at the model’s knowledge boundary, where the lack of memorized facts interacts with alignment pressure to produce polished but incorrect outputs.
Key takeaways
- Noisy data, long-tail gaps, and lossy compression seed latent errors in pre-training.
- These structural vulnerabilities remain hidden until they activate during inference.
Activation - The Moment Hallucination Is Seeded
Hallucinations that emerge during the Inference (Activation) Stage—also referred to as the decoding stage—arise from how the model selects tokens, manages uncertainty, and maintains coherence under autoregressive generation. Unlike training-time hallucinations, which stem from dataset artifacts or model misalignment, inference-time hallucinations are manifestations of real-time generative dynamics and the structural limitations of autoregressive decoding.
Uncertainty Mismanagement and Overconfidence
A core driver of inference-time hallucination is the model’s inability to accurately represent or communicate when it does not know something. LLMs lack mechanisms for tracking epistemic uncertainty—awareness of what they do or do not know — and must still output a token at every step. This creates a systemic bias toward confident fabrication.
-
Lack of Cognitive Uncertainty Estimation: LLMs do not have a built-in system for judging when their knowledge is incomplete. Instead of signaling “I am unsure,” they generate confident answers even when their internal evidence is weak. This happens because the softmax layer, which converts internal model scores into probabilities, tends to exaggerate small differences in logits, producing artificially high confidence. The model confidently misidentifies financial abbreviations, explains concepts incorrectly, and fabricates stock prices despite lacking factual grounding. These outputs show that the model’s surface-level confidence does not reflect its internal uncertainty—an effect amplified by training objectives that prioritize fluent continuation over truthfulness.
-
Internal–External Belief Mismatch: Even when the model’s internal activations contain signals indicating uncertainty or a high likelihood of error, these signals rarely influence the final generated text. In other words, the model may internally “sense” that an answer is unreliable, but the decoding stage still selects a confident-sounding token because it is the locally most probable continuation. This disconnect between internal representations and external behavior results in confident hallucinations, since the output layer does not faithfully convey the uncertainty embedded in the hidden states.
-
Incentivized Guessing: Because standard training objectives require a next token at every step—and because benchmarks and reward models strongly favor fluency and decisiveness—the model is conditioned to guess whenever it lacks information.
- Uncertainty is punished: “I’m not sure” or abstention is treated as an inferior answer in both SFT and RLHF/DPO.
- Confidence is rewarded: Detailed, fluent answers yield higher reward even when incorrect.
- Guessing becomes optimal: Faced with uncertainty, the model learns that fabrication is a reward-maximizing behavior.
This dynamic is demonstrated clearly in the TruthRL work: an SFT/RLHF-trained model confidently invents a false visa requirement rather than acknowledging insufficient knowledge. In contrast, TruthRL’s modified reward function treats abstention as neutral and penalizes confident hallucinations—causing the model to withhold an answer when it detects uncertainty. The example reveals a deeper truth: current training incentives systematically encourage confident hallucination, whereas alternative reward structures can restore calibrated, uncertainty-aware behavior.

Figure 10: A vanilla SFT/RL model confidently asserts an incorrect visa requirement rather than admitting insufficient information.
Decoding Dynamics and Token Selection Errors
Autoregressive token generation introduces several vulnerabilities tied directly to decoding strategy:
-
Stochastic sampling and amplified randomness.
Randomized samplers (top-k, top-p/nucleus, temperature-scaled sampling) intentionally inject noise to increase diversity. That same randomness, however, raises the probability of selecting low-likelihood or semantically implausible “tail” tokens: when the model’s distribution places nontrivial mass on many low-probability tokens, sampling can pick one of them and the continuation can cascade into factual errors or nonsensical assertions. This trade-off between diversity and fidelity is well documented in practitioner guides and technical write-ups.
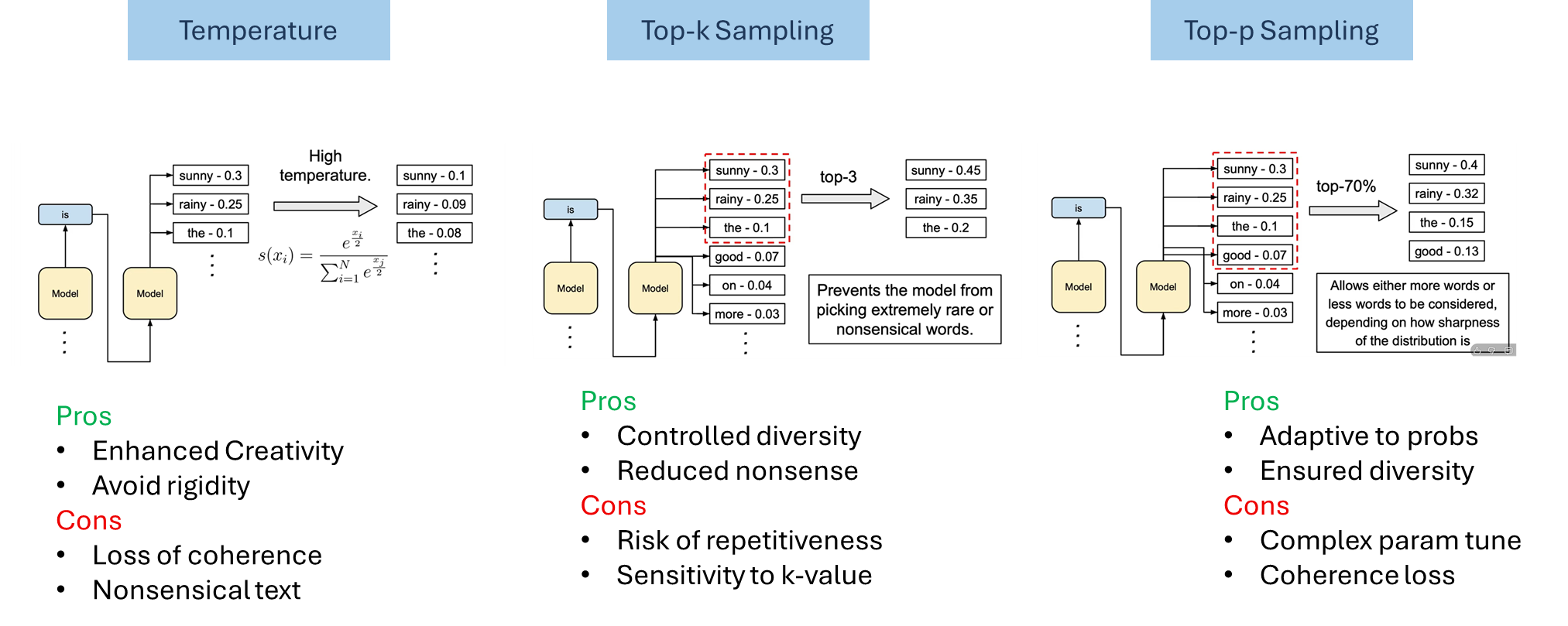
Figure 11: Selection of sampling approaches and their parameters directly reflects on hallucination chances.
-
High temperature flattens distributions and invites tail-token mistakes.
Raising temperature smooths (flattens) the softmaxed logits so weaker options become more likely. At moderate to high temperatures the model is much more likely to pick tail tokens that were previously negligible, which increases semantic drift and the chance that the model “fills in” missing facts with invented details. Recent papers and surveys show this effect empirically and motivate dynamic truncation samplers (e.g., min-p) that try to preserve creativity without inviting incoherence.
-
Softmax bottleneck limits expressive conditional distributions.
The standard linear + softmax prediction head can be unable to represent high-rank, multi-modal next-token distributions that real language contexts sometimes demand. This representational constraint (the “softmax bottleneck”) means the model’s output distribution can be structurally mismatched to the true set of plausible continuations, which decoding heuristics then exacerbate — occasionally pushing the model toward compact but incorrect modes or forcing it to approximate multi-modal uncertainty with single, overconfident peaks that later get sampled into fabrication. Work analyzing and attempting to break the softmax bottleneck documents how this architectural limit contributes to mis-selection of tokens in semantically rich contexts.
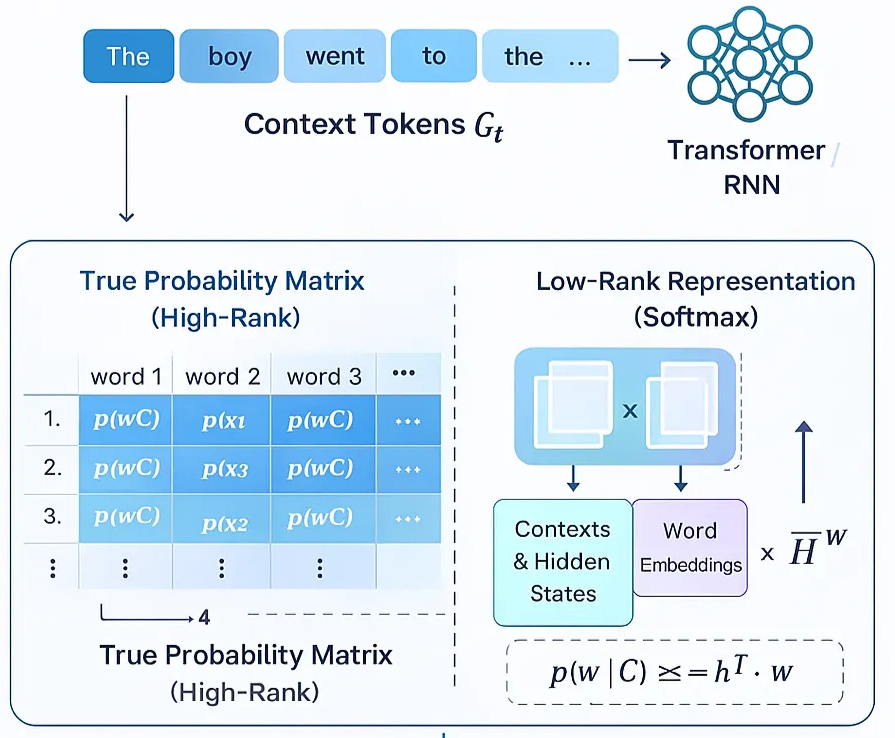
Figure 12: Softmax bottleneck impacts the model’s response and its capability to utilize all contexts.
-
Unidirectional contextualization encourages gap-filling via fabrication.
Autoregressive models predict the next token from a single hidden state that summarizes past context. When the prompt or context is ambiguous, incomplete, or weakly grounded, the model often fills gaps with the most probabilistically plausible continuation rather than signalling uncertainty. That behavior — effectively “confident guessing” — produces fluent but ungrounded continuations (extrinsic hallucinations) that look correct yet are unsupported by evidence. Analyses of hallucination sources and sampling-based detection techniques highlight how incomplete context plus stochastic decoding leads to fabricated facts.
Key takeaways
- LLMs lack epistemic uncertainty awareness and often output confident guesses.
- Internal uncertainty signals rarely shape the final token, leading to early seeded hallucinations.
Drift - Compounding Errors
Once an LLM enters autoregressive generation, it transitions into a regime fundamentally unlike the one it was trained on. In this Drift phase, small early deviations can escalate into full hallucinations as the model’s output becomes its own input. Trajectory drift arises from three interacting forces: sequential error propagation, architectural limits in maintaining focus, and the absence of real-time self-correction.
Exposure Bias: The Engine of Drift
The fundamental driver of compounding errors during generation is Exposure Bias—the misalignment between how LLMs are trained and how they are used at inference time. During training, models rely on teacher-forced ground-truth prefixes, meaning they only ever see clean, correct contexts and never confront the consequences of their own mistakes. At inference, however, the model must condition each new token on the sequence it has generated so far—including its errors. A single early mistake (such as a misidentified entity) becomes part of the model’s assumed context, and because the system was never trained on its own flawed outputs, it has no mechanism to detect or correct this deviation. This mismatch produces the classic “snowball effect”: once a hallucinated token enters the sequence, the model treats it as factual, and the deviation from the true trajectory amplifies with each subsequent step, especially in longer or more complex generations.
Compounding Errors and Trajectory Propagation
Given this mismatch, hallucinations behave like trajectory attractors—once the model drifts, it tends to drift further.
- Increased Hallucination Chance: When a generated sentence is hallucinated, the chances of hallucination in the subsequently generated sentences increase. This relationship is demonstrated empirically: a generated sentence is hallucinated more often when there has already been hallucination in the previously generated sentences.
- Fidelity Degradation over Length: As sequences grow, factual stability declines, especially in multi-hop reasoning or long-form summarization. Detecting and correcting errors as they arise is therefore crucial; otherwise, errors propagate forward and deteriorate the entire generation.
Architectural and Decoding Weaknesses
The decoding process itself introduces vulnerabilities that enable and amplify trajectory drift:
- Attention Attenuation (Focus Dilution): During the generation of long sequences, the soft attention mechanisms in the Transformer architecture can result in hallucination. As the sequence length ($N$) increases, attention weights tend to become more diffuse. This forces the model to distribute focus between less relevant tokens, causing focus dilution and ultimately leading to degraded reasoning or factual inaccuracies.
- Erroneous Decoding and Entity Confusion: The decoder, whose role is to take the encoded input and generate the final sequence, can contribute to drift if it attends to the wrong part of the encoded input source. Such a wrong association can result in generated text with facts mixed up between two similar entities.
- Stochastic Sampling: While decoding strategies that introduce randomness (like Top-K or Nucleus sampling) increase diversity and creativity, they are positively correlated with increased hallucination. Introducing randomness increases the risk of selecting low-probability tokens that diverge from factual correctness.
Lack of Real-Time Self-Correction
A critical factor that permits the drift to continue unchecked is the absence of internal mechanisms to pause or verify content once generation has begun.
- Uncertainty Signal Ignored: Although internal activations often contain indicators of uncertainty or potential error, these signals do not meaningfully influence token selection. The decoding layer simply chooses the most probable next token—even when the model internally “knows” the situation is unstable.
- Failure to Hesitate: Humans exhibit hesitation before responding to queries when they know they are uncertain. However, since LLMs lack this self-awareness process, they frequently activate flawed priors and respond with fluent but incorrect guesses. This lack of a built-in “hesitation” mechanism allows the initial error to go uncorrected and begin the process of trajectory drift.
Key takeaways
- Once a wrong token enters the context, exposure bias makes the model amplify it.
- Attention dilution and stochastic decoding accelerate drift away from factual ground truth.
Divergence - Overconfidence and Self-Reinforcement
The Divergence phase captures the moment where fundamental mathematical and architectural limits surface during token-by-token generation. Here, hallucination no longer results from missing knowledge (as in Pre-training) or misaligned incentives (as in Alignment); instead, it arises from structural violations of information-aggregation principles within the Transformer itself. These violations create unavoidable overconfidence and unstable fusion of competing internal signals.
Mathematical Divergence and the Jensen Gap
Transformers aggregate heterogeneous signals—attention head outputs, MLP projections, and modality encoders—through log-sum-exp (LSE) operations. This aggregation introduces a structural vulnerability called the Jensen Gap.
Violation of Semantic Information Conservation
Each attention head produces a distinct logit distribution representing a “perspective” on the next token. When these logits are aggregated through the LSE function:
-
Convexity of LSE guarantees that
$$\text{LSE}\left(\sum_{h=1}^{H} \ell_h \right) \ge\sum_{h=1}^{H}\text{LSE}(\ell_h)$$ -
The resulting difference is the Jensen Gap
$$\Gamma = \text{LSE}\left(\sum_h \ell_h\right) - \sum_h \text{LSE}(\ell_h) \gt 0$$
The Jensen Gap (Γ): The resulting difference, Γ, known as the Jensen Gap, is always positive (Γ>0) when the underlying beliefs of the components (heads) differ.
This reveals an impossibility theorem: no LLM can simultaneously maintain truthful responses, preserve semantic information, reveal relevant knowledge, and decode optimally under computational bounds. The architecture is forced to violate at least one of these principles.
Overconfidence Produced by the Jensen Gap
The Jensen gap induces systematic excess confidence, producing predictions that appear more certain than any individual head can substantiate.
Example:
If Head 1 predicts fox with probability 48% and Head 2 predicts 14.7%, a linear aggregation suggests a probability around 31%. After LSE fusion, the final probability might be 38%—a surplus of +7 percentage points originating purely from the Jensen gap.
This surplus is the hallucination: an architectural overstatement of certainty.
Theoretical Impossibility and Creativity–Hallucination Duality
Structural Impossibility of Perfect Control
Because of the Jensen Gap, LLMs face a built-in contradiction: the mathematical requirements for perfect hallucination control are mutually incompatible. No inference mechanism can simultaneously ensure:
- Truthful response generation
- Semantic information conservation
- Relevance-preserving knowledge use
- Optimal decoding under bounded computation
Thus, hallucination is not a removable defect—it is a necessary consequence of how Transformer-based models integrate distributed knowledge.
Creativity–Hallucination Duality
The same convex LSE aggregation that produces the Jensen Gap also enables generative flexibility. The surplus Γ:
- allows the model to synthesize divergent perspectives, interpolate missing structure, and generate creative inferences; but
- also destabilizes semantic fidelity by inflating confidence beyond the evidence.
Therefore, creativity and hallucination are mathematically coupled. The very mechanism that enables open-ended generation is the one that causes unsupported assertions. Hallucination is thus intrinsic and unavoidable, not merely a behavior to be corrected.
Divergence as Generalization Error
The theoretical impossibility established by the Jensen Gap aligns with the view that hallucination during divergence is a form of generalization error, specifically quantified by the difference between the model’s behavior and the ideal truth.
Hallucinations correspond to deviations between the model distribution ($Q$) and the ideal ground-truth distribution ($P$), bounded by:
$$\text{Err} \propto \sqrt{KL(Q \parallel P)}$$Since reducing hallucination requires reducing the KL divergence between the model’s behavior and the ideal truth, this effort is constrained by model size, parameterization, and training data. The KL divergence term in generalization bounds penalizes models that deviate significantly from prior knowledge, capturing a complexity-accuracy trade-off.
Key takeaways
- The Jensen Gap in log-sum-exp aggregation mathematically inflates confidence.
- This structural surplus couples creativity and hallucination, making perfect control impossible.
Towards Closed-Loop LLMs: Introducing Feedback and Error Correction
Mitigating hallucinations requires reframing LLMs not as open-loop generators—which produce outputs without monitoring or correction—but as closed-loop systems that continuously sense, regulate, and refine their behavior during inference. A closed-loop LLM introduces three essential components:
- An Observer (Error Detection): a mechanism for detecting hallucination risk from the model’s internal activations.
- An Actuator (Dynamic Control): an inference-time controller that modulates attention or logits to maintain factual alignment.
- A Feedback Loop (Iterative Correction): an iterative refinement process that verifies, revises, and stabilizes the generation.
The Observer: Internal Sensing for Hallucination Detection
A closed-loop system begins by measuring what is happening internally. LLMs naturally encode rich activation patterns that reveal when the model is at risk of drifting into hallucination.
- Activation-based self-assessment: Internal layers indicate whether the model has seen a query during pre-training and whether it is likely to hallucinate.
- Depth correlation: Probing studies show that deeper layers yield the most accurate hallucination predictions, capturing high-level uncertainty patterns.
- Early warning signal: These indicators can be computed before any token is generated, enabling proactive error detection.
In engineering terms, the Observer provides an error signal analogous to a sensor reporting deviation from a stable setpoint—crucial for closed-loop control.
The Actuator: Dynamic Inference-Time Control
Once uncertainty or drift risk is detected, the system must apply real-time corrective action during decoding.
PID-Style Attention Control (COMPASS)
COMPASS uses a Context Reliance Score (CRS) to estimate factual grounding and feeds this signal into a PID controller.
The controller computes a gain $\rho_t$ that applies a subtle pre-softmax correction to attention heads, steering the model toward evidence-supported tokens.
Contrastive Logit Modulation
These methods reshape the token distribution based on internal knowledge conflicts:
- DoLa: contrasts mature vs. early layer logits to amplify factual knowledge.
- CAD: contrasts outputs with and without context to suppress misleading parametric priors.
From a control perspective, these methods inject corrective forces into the system’s unfolding trajectory, stabilizing generation as it evolves.
The Feedback Loop: Iterative Correction and Refinement
A genuine closed-loop system requires continuous correction, not one-shot intervention. Several emerging frameworks implement multi-step refinement cycles:
- Generate → Detect → Mitigate loops: The model drafts an output, a detector flags inconsistencies, and a mitigation step revises or retrieves missing information.
- Chain-of-Verification (CoVe): The model generates verification questions, answers them independently, and reconciles inconsistencies—a self-supervised feedback loop.
- Iterative Retrieval (RAG): Retrieval is triggered dynamically based on ongoing generation, ensuring evidence supply throughout long reasoning chains.
- Cross-model feedback (FINCH-ZK, UAF): Ensembles compare responses across models, identify inconsistencies, and fuse stable segments into a corrected final answer.
These mechanisms introduce iterative stability corrections, directly counteracting the divergence dynamics of open-loop generation.
Key takeaways
- Adding observers, actuators, and feedback loops introduces real-time correction.
- Such systems can stabilize generation and mitigate the failure cascade of open-loop decoding.
Ethical Considerations and Real-World Applications
Hallucinations are not merely technical defects—they carry serious ethical and societal risks. In domains such as medicine, law, finance, and public policy, hallucinated details can lead to harmful decisions, misdiagnoses, financial loss, or legal violations.
Closed-loop LLMs—equipped with real-time sensing, control, and feedback—offer a pathway toward safer and more trustworthy AI systems. By reducing hallucination risk and improving factual stability, they help ensure AI systems can be deployed responsibly in high-stakes environments where the cost of error is significant.
Conclusion
In this work, we reframed hallucinations in LLMs as a direct consequence of their open-loop generative architecture, showing that these failures are not random anomalies but predictable outcomes of structural constraints in training, inference, and information aggregation. Without mechanisms for sensing, feedback, and correction, even state-of-the-art models have no means to detect or counteract their own drift. By introducing a closed-loop paradigm—featuring internal observers for uncertainty detection, actuators for real-time control, and iterative feedback loops for refinement—we outlined a path toward more reliable, self-stabilizing LLMs that actively monitor and regulate their own behavior, reducing the risk of harmful hallucinations in high-stakes applications.
Looking forward, advancing this paradigm raises several key research directions: integrating real-time feedback mechanisms into existing transformer architectures; empirically validating how observer–actuator–feedback designs influence stability, hallucination rates, and task performance across domains; and addressing the ethical implications of deploying self-correcting systems in fields such as medicine, law, and finance where transparency, fairness, and safety are paramount. Progress here will also require new benchmarks that evaluate stability under drift, uncertainty calibration, and correction effectiveness. Together, these lines of inquiry point toward a new generation of trustworthy, self-correcting LLMs—systems that are not only powerful, but robust, aligned, and prepared for responsible real-world use.